Portfolio Optimization in Python
In this post we will demonstrate how to use python to calculate the optimal portfolio and visualize the efficient frontier.
In this post we will only show the code with minor explanations.
Lets begin with loading the modules.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pandas_datareader as webNext we will get the stock tickers and the price data.
tick = ['AMZN', 'AAPL', 'NFLX', 'XOM', 'T']
price_data = web.get_data_yahoo(tick,
start = '2014-01-01',
end = '2018-05-31')['Adj Close']Now lets calculate the log returns.
log_ret = np.log(price_data/price_data.shift(1))Next we will calculate the covariance matrix.
cov_mat = log_ret.cov() * 252
print(cov_mat)## Symbols AAPL AMZN NFLX T XOM
## Symbols
## AAPL 0.052338 0.023844 0.026897 0.008896 0.012677
## AMZN 0.023844 0.086810 0.048926 0.007808 0.012902
## NFLX 0.026897 0.048926 0.175844 0.008173 0.013306
## T 0.008896 0.007808 0.008173 0.026032 0.010989
## XOM 0.012677 0.012902 0.013306 0.010989 0.034014Next we will jump right into the for loop and simulate the portfolio returns and risk on 5000 random portfolios. If you need the further explanation, please see the code in R.
# Simulating 5000 portfolios
num_port = 5000
# Creating an empty array to store portfolio weights
all_wts = np.zeros((num_port, len(price_data.columns)))
# Creating an empty array to store portfolio returns
port_returns = np.zeros((num_port))
# Creating an empty array to store portfolio risks
port_risk = np.zeros((num_port))
# Creating an empty array to store portfolio sharpe ratio
sharpe_ratio = np.zeros((num_port))Lets run the for loop.
for i in range(num_port):
wts = np.random.uniform(size = len(price_data.columns))
wts = wts/np.sum(wts)
# saving weights in the array
all_wts[i,:] = wts
# Portfolio Returns
port_ret = np.sum(log_ret.mean() * wts)
port_ret = (port_ret + 1) ** 252 - 1
# Saving Portfolio returns
port_returns[i] = port_ret
# Portfolio Risk
port_sd = np.sqrt(np.dot(wts.T, np.dot(cov_mat, wts)))
port_risk[i] = port_sd
# Portfolio Sharpe Ratio
# Assuming 0% Risk Free Rate
sr = port_ret / port_sd
sharpe_ratio[i] = srNow that all the heavy lifting has been done. We will start by getting the minimum variance portfolio and the tangency portfolio.
names = price_data.columns
min_var = all_wts[port_risk.argmin()]
print(min_var)## [0.1479928 0.08456108 0.01861031 0.43988479 0.30895102]max_sr = all_wts[sharpe_ratio.argmax()]
print(max_sr)## [0.33134387 0.38121158 0.23987104 0.04371634 0.00385717]Lets see the max sharpe ratio and the minimum risk for these portfolios
print(sharpe_ratio.max())## 1.5976782731708208print(port_risk.min())## 0.13362971668665094Since we are only simulating 5000 portfolio, it very likely our allocations and our sharpe ratios/risk metrics will be different than what we got on the last post in R. The point of this exercise is to demonstrate the underlying process of getting optimal portfolio. If we need more accuracy then we need to use optimization packages instead of this trial and error method described in this post.
Now lets visualize the weights of the portfolio. First we will visualize the minimum variance portfolio.
min_var = pd.Series(min_var, index=names)
min_var = min_var.sort_values()
fig = plt.figure()
ax1 = fig.add_axes([0.1,0.1,0.8,0.8])
ax1.set_xlabel('Asset')
ax1.set_ylabel("Weights")
ax1.set_title("Minimum Variance Portfolio weights")
min_var.plot(kind = 'bar')
plt.show();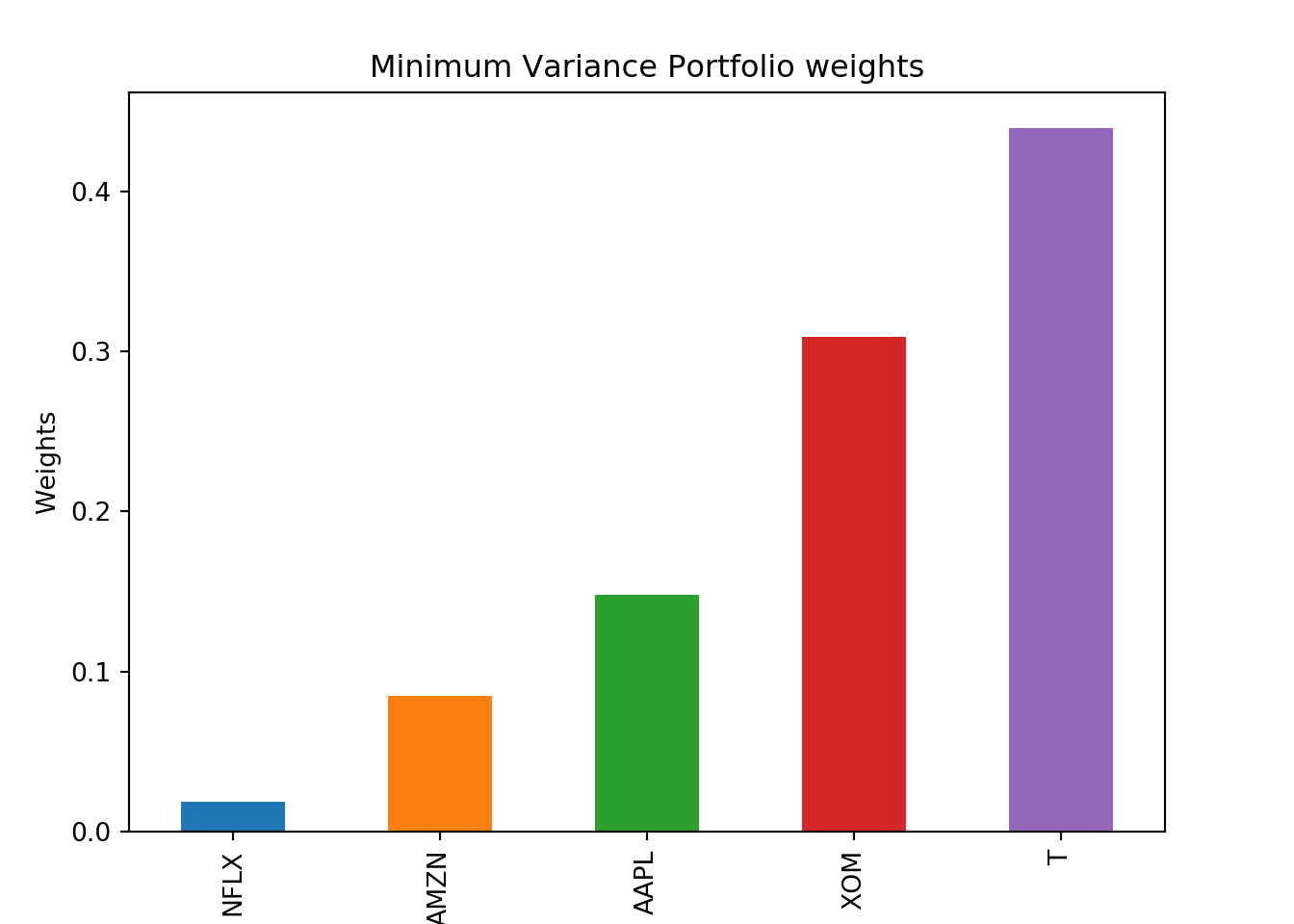
Next we will visualize the max sharpe ratio portfolio.
max_sr = pd.Series(max_sr, index=names)
max_sr = max_sr.sort_values()
fig = plt.figure()
ax1 = fig.add_axes([0.1,0.1,0.8,0.8])
ax1.set_xlabel('Asset')
ax1.set_ylabel("Weights")
ax1.set_title("Tangency Portfolio weights")
max_sr.plot(kind = 'bar')
plt.show();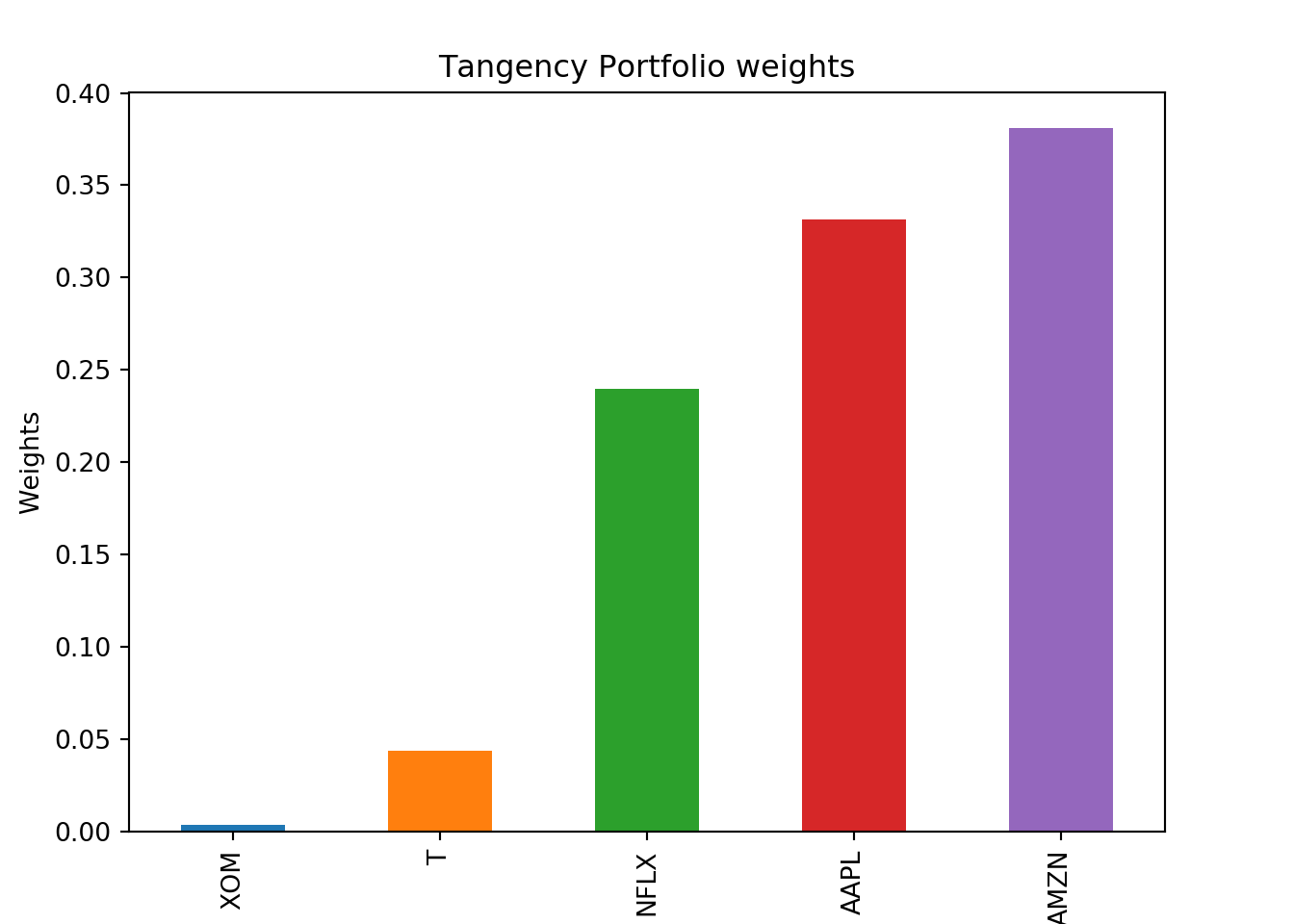
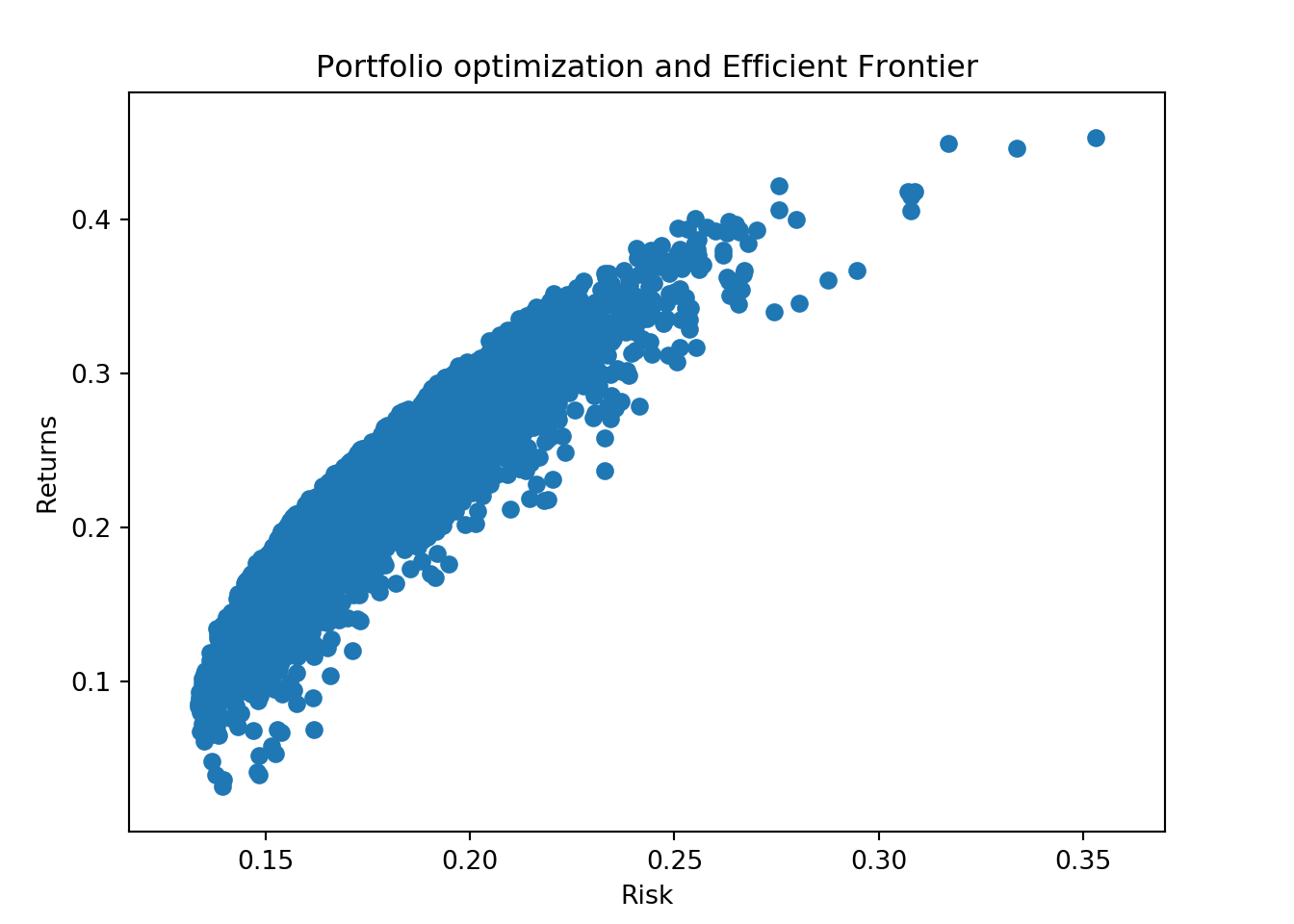
Finally we can plot all the 5000 portfolios.
fig = plt.figure()
ax1 = fig.add_axes([0.1,0.1,0.8,0.8])
ax1.set_xlabel('Risk')
ax1.set_ylabel("Returns")
ax1.set_title("Portfolio optimization and Efficient Frontier")
plt.scatter(port_risk, port_returns)
plt.show();